🤖 browser-use
➤ AI浏览器代理,可点击/登录/填表/操作网页
➤ 像真人一样执行复杂网页任务
➤ ETH团队开发
🔗 https://github.com/browser-use/browser-use ———
🧱 Crawlee
➤ 生产级爬虫框架(Apify)
➤ 支持代理轮换 / 自动重试 / 队列管理
➤ 反封禁能力完善
🔗 https://github.com/apify/crawlee ———
🐍 Scrapy
➤ 工业级爬虫框架
➤ 支持百万级网页抓取
➤ 数据采集稳定成熟
🔗 https://github.com/scrapy/scrapy ———
📄 MarkItDown
➤ 多格式转 Markdown(网页/PDF/Office/图片)
➤ AI数据处理标准化工具
🔗 https://github.com/microsoft/markitdown ———
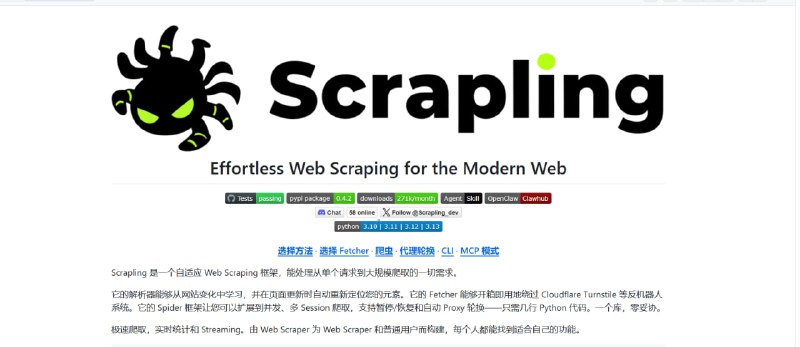
🧠 Scrapling
➤ 自适应反爬框架
➤ 自动适配网站结构变化
➤ 提升稳定性
🔗 https://github.com/D4Vinci/Scrapling ———
📱 scrcpy
➤ 安卓远程控制工具
➤ 用于移动端数据采集/自动化
🔗 https://github.com/Genymobile/scrcpy ———
🔍 AutoScraper
➤ 自动规则爬虫(无需写选择器)
➤ 输入样本自动学习规则
🔗 https://github.com/alirezamika/autoscraper ———
🌐 curl_cffi
➤ 浏览器级HTTP请求库
➤ 模拟真实Chrome指纹(TLS/JA3)
➤ 反检测能力强
🔗 https://github.com/lexiforest/curl_cffi